January, 2023
2023-01-01
- Apply some more ORCID identifiers to items on CGSpace using my
2022-09-22-add-orcids.csvfile- I want to update all ORCID names and refresh them in the database
- I see we have some new ones that aren’t in our list if I combine with this file:
$ cat dspace/config/controlled-vocabularies/cg-creator-identifier.xml | grep -oE '[A-Z0-9]{4}-[A-Z0-9]{4}-[A-Z0-9]{4}-[A-Z0-9]{4}' | sort -u | wc -l
1939
$ cat dspace/config/controlled-vocabularies/cg-creator-identifier.xml 2022-09-22-add-orcids.csv | grep -oE '[A-Z0-9]{4}-[A-Z0-9]{4}-[A-Z0-9]{4}-[A-Z0-9]{4}' | sort -u | wc -l
1973
- I will extract and process them with my
resolve-orcids.pyscript:
$ cat dspace/config/controlled-vocabularies/cg-creator-identifier.xml 2022-09-22-add-orcids.csv| grep -oE '[A-Z0-9]{4}-[A-Z0-9]{4}-[A-Z0-9]{4}-[A-Z0-9]{4}' | sort -u > /tmp/2023-01-01-orcids.txt
$ ./ilri/resolve-orcids.py -i /tmp/2023-01-01-orcids.txt -o /tmp/2023-01-01-orcids-names.txt -d
- Then update them in the database:
$ ./ilri/update-orcids.py -i /tmp/2023-01-01-orcids-names.txt -db dspace -u dspace -p 'fuuu' -m 247
- Load on CGSpace is high around 9.x
- I see there is a CIAT bot harvesting via the REST API with IP 45.5.186.2
- Other than that I don’t see any particular system stats as alarming
- There has been a marked increase in load in the last few weeks, perhaps due to Initiative activity…
- Perhaps there are some stuck PostgreSQL locks from CLI tools?
$ psql -c 'SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa ON pl.pid = psa.pid;' | grep -o -E '(dspaceWeb|dspaceApi|dspaceCli)' | sort | uniq -c
58 dspaceCli
46 dspaceWeb
- The current time on the server is 08:52 and I see the dspaceCli locks were started at 04:00 and 05:00… so I need to check which cron jobs those belong to as I think I noticed this last month too
- I’m going to wait and see if they finish, but by tomorrow I will kill them
2023-01-02
- The load on the server is now very low and there are no more locks from dspaceCli
- So there was some long-running process that was running and had to finish!
- That finally sheds some light on the “high load on Sunday” problem where I couldn’t find any other distinct pattern in the nginx or Tomcat requests
2023-01-03
- The load from the server on Sundays, which I have noticed for a long time, seems to be coming from the DSpace checker cron job
- This checks the checksums of all bitstreams to see if they match the ones in the database
- I exported the entire CGSpace metadata to do country/region checks with
csv-metadata-quality- I extracted only the items with countries, which was about 48,000, then split the file into parts of 10,000 items, but the upload found 2,000 changes in the first one and took several hours to complete…
- IWMI sent me ORCID identifiers for new scientsts, bringing our total to 2,010
2023-01-04
- I finally finished applying the region imports (in five batches of 10,000)
- It was about 7,500 missing regions in total…
- Now I will move on to doing the Initiative mappings
- I modified my
fix-initiative-mappings.pyscript to only write out the items that have updated mappings - This makes it way easier to apply fixes to the entire CGSpace because we don’t try to import 100,000 items with no changes in mappings
- I modified my
- More dspaceCli locks from 04:00 this morning (current time on server is 07:33) and today is a Wednesday
- The checker cron job runs on
0,3, which is Sunday and Wednesday, so this is from that… - Finally at 16:30 I decided to kill the PIDs associated with those locks…
- I am going to disable that cron job for now and watch the server load for a few weeks
- The checker cron job runs on
- Start a harvest on AReS
2023-01-08
- It’s Sunday and I see some PostgreSQL locks belonging to dspaceCli that started at 05:00
- That’s strange because I disabled the
dspace checkerone last week, so I’m not sure which this is… - It’s currently 2:30PM on the server so these locks have been there for almost twelve hours
- That’s strange because I disabled the
- I exported the entire CGSpace to update the Initiative mappings
- Items were mapped to ~58 new Initiative collections
- Then I ran the ORCID import to catch any new ones that might not have been tagged
- Then I started a harvest on AReS
2023-01-09
- Fix some invalid Initiative names on CGSpace and then check for missing mappings
- Check for missing regions in the Initiatives collection
- Export a list of author affiliations from the Initiatives community for Peter to check
- Was slightly ghetto because I did it from a CSV export of the Initiatives community, then imported to OpenRefine to split multi-value fields, then did some sed nonsense to handle the quoting:
$ csvcut -c 'cg.contributor.affiliation[en_US]' ~/Downloads/2023-01-09-initiatives.csv | \
sed -e 's/^"//' -e 's/"$//' -e 's/||/\n/g' | \
sort -u | \
sed -e 's/^\(.*\)/"\1/' -e 's/\(.*\)$/\1"/' > /tmp/2023-01-09-initiatives-affiliations.csv
2023-01-10
- Export the CGSpace Initiatives collection to check for missing regions and collection mappings
2023-01-11
- I’m trying the DSpace 7 REST API again
- While following onathe DSpace 7 REST API authentication docs I still cannot log in via curl on the command line because I get a
Access is denied. Invalid CSRF token.message - Logging in via the HAL Browser works…
- Someone on the DSpace Slack mentioned that the authentication documentation is out of date and we need to specify the cookie too
- I tried it and finally got it to work:
- While following onathe DSpace 7 REST API authentication docs I still cannot log in via curl on the command line because I get a
$ curl --head https://dspace7test.ilri.org/server/api
...
set-cookie: DSPACE-XSRF-COOKIE=42c78c56-613d-464f-89ea-79142fc5b519; Path=/server; Secure; HttpOnly; SameSite=None
dspace-xsrf-token: 42c78c56-613d-464f-89ea-79142fc5b519
$ curl -v -X POST https://dspace7test.ilri.org/server/api/authn/login --data "user=alantest%40cgiar.org&password=dspace" -H "X-XSRF-TOKEN: 42c78c56-613d-464f-89ea-79142fc5b519" -b "DSPACE-XSRF-COOKIE=42c78c56-613d-464f-89ea-79142fc5b519"
...
authorization: Bearer eyJh...9-0
$ curl -v "https://dspace7test.ilri.org/api/core/items" -H "Authorization: Bearer eyJh...9-0"
- I created a pull request to fix the docs
- I did quite a lot of cleanup and updates on the IFPRI batch items for the Gender Equality batch upload
- Then I uploaded them to CGSpace
- I added about twenty more ORCID identifiers to my list and tagged them on CGSpace
2023-01-12
- I exported the entire CGSpace and did some cleanups on all metadata in OpenRefine
- I was primarily interested in normalizing the DOIs, but I also normalized a bunch of publishing places
- After this imports I will export it again to do the Initiative and region mappings
- I ran the
fix-initiative-mappings.pyscript and got forty-nine new mappings…
- I added several dozen new ORCID identifiers to my list and tagged ~500 on CGSpace
- Start a harvest on AReS
2023-01-13
- Do a bit more cleanup on licenses, issue dates, and publishers
- Then I started importing my large list of 5,000 items changed from yesterday
- Help Karen add abstracts to a bunch of SAPLING items that were missing them on CGSpace
- For now I only did open access journal articles, but I should do the reports and others too
2023-01-14
- Export CGSpace and check for missing Initiative mappings
- There were a total of twenty-five
- Then I exported the Initiatives communinty to check the countries and regions
2023-01-15
- Start a harvest on AReS
2023-01-16
- Batch import four IFPRI items for CGIAR Initiative on Low-Emission Food Systems
- Batch import another twenty-eight items for IFPRI across several Initiatives
- On this one I did quite a bit of extra work to check for CRPs and data/code URLs in the acknowledgements, licenses, volume/issue/extent, etc
- I fixed some authors, an ISBN, and added extra AGROVOC keywords from the abstracts
- Then I checked for duplicates and ran it through csv-metadata-quality to make sure the countries/regions matched and there were no duplicate metadata values
2023-01-17
- Batch import another twenty-three items for IFPRI across several Initiatives
- I checked the IFPRI eBrary for extra CRPs and data/code URLs in the acknowledgements, licenses, volume/issue/extent, etc
- I fixed some authors, an ISBN, and added extra AGROVOC keywords from the abstracts
- Then I found and removed one duplicate in these items, as well as another on CGSpace already (!): 10568/126669
- Then I ran it through csv-metadata-quality to make sure the countries/regions matched and there were no duplicate metadata values
- I exported the Initiatives collection to check the mappings, regions, and other metadata with csv-metadata-quality
- I also added a bunch of ORCID identifiers to my list and tagged 837 new metadata values on CGSpace
- There is a high load on CGSpace pretty regularly
- Looking at Munin it shows there is a marked increase in DSpace sessions the last few weeks:
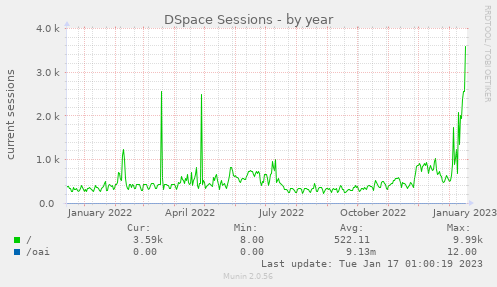
- Is this attributable to all the PRMS harvesting?
- I also see some PostgreSQL locks starting earlier today:
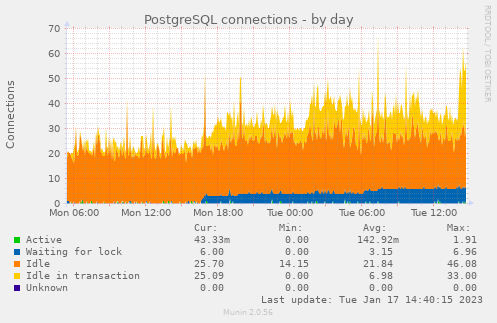
- I’m curious to see what kinds of IPs have been connecting, so I will look at the last few weeks:
# zcat --force /var/log/nginx/{rest,access,library-access,oai}.log /var/log/nginx/{rest,access,library-access,oai}.log.1 /var/log/nginx/{rest,access,library-access,oai}.log.{2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25}.gz | awk '{print $1}' | sort | uniq > /tmp/2023-01-17-cgspace-ips.txt
# wc -l /tmp/2023-01-17-cgspace-ips.txt
129446 /tmp/2023-01-17-cgspace-ips.txt
- I ran the IPs through my
resolve-addresses-geoip2.pyscript to resolve their ASNs/networks, then extracted some lists of data center ISPs by eyeballing them (Amazon, Google, Microsoft, Apple, DigitalOcean, HostRoyale, and a dozen others):
$ csvgrep -c asn -r '^(8075|714|16276|15169|23576|24940|13238|32934|14061|12876|55286|203020|204287|7922|50245|6939|16509|14618)$' \
/tmp/2023-01-17-cgspace-ips.csv | csvcut -c network | \
sed 1d | sort | uniq > /tmp/networks-to-block.txt
$ wc -l /tmp/networks-to-block.txt
776 /tmp/networks-to-block.txt
- I added the list of networks to nginx’s
bot-networks.confso they will all be heavily rate limited - Looking at the Munin stats again I see the load has been extra high since yesterday morning:
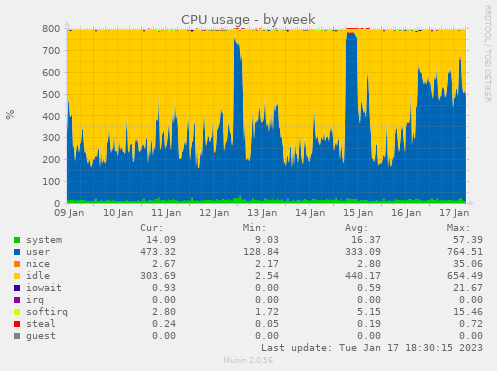
- But still, it’s suspicious that there are so many PostgreSQL locks
- Looking at the Solr stats to check the hits the last month (actually I skipped December because I was so busy)
- I see 31.148.223.10 is on ALFA TELECOM s.r.o. in Russia and it made 43,000 requests this month (and 400,000 more last month!)
- I see 18.203.245.60 is on Amazon and it uses weird user agents, different with each request
- I see 3.249.192.212 is on Amazon and it uses weird user agents, different with each request
- I see 34.244.160.145 is on Amazon and it uses weird user agents, different with each request
- I see 52.213.59.101 is on Amazon and it uses weird user agents, different with each request
- I see 91.209.8.29 is in Bulgaria on DGM EOOD and is low risk according to Scamlytics, but their user agent is all lower case and it’s a data center ISP so nope
- I see 54.78.176.127 is on Amazon and it uses weird user agents, different with each request
- I see 54.246.128.111 is on Amazon and it uses weird user agents, different with each request
- I see 54.74.197.53 is on Amazon and it uses weird user agents, different with each request
- I see 52.16.103.133 is on Amazon and it uses weird user agents, different with each request
- I see 63.32.99.252 is on Amazon and it uses weird user agents, different with each request
- I see 176.34.141.181 is on Amazon and it uses weird user agents, different with each request
- I see 34.243.17.80 is on Amazon and it uses weird user agents, different with each request
- I see 34.240.206.16 is on Amazon and it uses weird user agents, different with each request
- I see 18.203.81.120 is on Amazon and it uses weird user agents, different with each request
- I see 176.97.210.106 is on Tube Hosting and is rate VERY BAD, malicious, scammy on everything I checked
- I see 79.110.73.54 is on ALFA TELCOM / Serverel and is using a different, weird user agent with each request
- There are too many to count… so I will purge these and then move on to user agents
- I purged hits from those IPs:
$ ./ilri/check-spider-ip-hits.sh -f /tmp/ips.txt -p
Purging 439185 hits from 31.148.223.10 in statistics
Purging 2151 hits from 18.203.245.60 in statistics
Purging 1990 hits from 3.249.192.212 in statistics
Purging 1975 hits from 34.244.160.145 in statistics
Purging 1969 hits from 52.213.59.101 in statistics
Purging 2540 hits from 91.209.8.29 in statistics
Purging 1624 hits from 54.78.176.127 in statistics
Purging 1236 hits from 54.74.197.53 in statistics
Purging 1327 hits from 54.246.128.111 in statistics
Purging 1108 hits from 52.16.103.133 in statistics
Purging 1045 hits from 63.32.99.252 in statistics
Purging 999 hits from 176.34.141.181 in statistics
Purging 997 hits from 34.243.17.80 in statistics
Purging 985 hits from 34.240.206.16 in statistics
Purging 862 hits from 18.203.81.120 in statistics
Purging 1654 hits from 176.97.210.106 in statistics
Purging 1628 hits from 51.81.193.200 in statistics
Purging 1020 hits from 79.110.73.54 in statistics
Purging 842 hits from 35.153.105.213 in statistics
Purging 1689 hits from 54.164.237.125 in statistics
Total number of bot hits purged: 466826
- Looking at user agents in Solr statistics from 2022-12 and 2023-01 I see some weird ones:
azure-logic-apps/1.0 (workflow e1f855704d6543f48be6205c40f4083f; version 08585300079823949478) microsoft-flow/1.0Gov employment data scraper ([[your email]])Microsoft.Data.Mashup (https://go.microsoft.com/fwlink/?LinkID=304225)crownpeakMozilla/5.0 (compatible)
- Also, a ton of them are lower case, which I’ve never seen before… it might be possible, but looks super fishy to me:
mozilla/5.0 (x11; ubuntu; linux x86_64; rv:84.0) gecko/20100101 firefox/86.0mozilla/5.0 (macintosh; intel mac os x 11_3) applewebkit/537.36 (khtml, like gecko) chrome/89.0.4389.90 safari/537.36mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/86.0.4240.75 safari/537.36mozilla/5.0 (windows nt 10.0; win64; x64; rv:86.0) gecko/20100101 firefox/86.0mozilla/5.0 (x11; linux x86_64) applewebkit/537.36 (khtml, like gecko) chrome/90.0.4430.93 safari/537.36mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/92.0.4515.159 safari/537.36mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/88.0.4324.104 safari/537.36mozilla/5.0 (x11; linux x86_64) applewebkit/537.36 (khtml, like gecko) chrome/86.0.4240.75 safari/537.36
- I purged some of those:
$ ./ilri/check-spider-hits.sh -f /tmp/agents.txt -p
Purging 1658 hits from azure-logic-apps\/1.0 in statistics
Purging 948 hits from Gov employment data scraper in statistics
Purging 786 hits from Microsoft\.Data\.Mashup in statistics
Purging 303 hits from crownpeak in statistics
Purging 332 hits from Mozilla\/5.0 (compatible) in statistics
Total number of bot hits purged: 4027
- Then I ran all system updates on the server and rebooted it
- Hopefully this clears the locks and the nginx mitigation helps with the load from non-human hosts in large data centers
- I need to re-work how I’m doing this whitelisting and blacklisting… it’s way too complicated now
- Export entire CGSpace to check Initiative mappings, and add nineteen…
- Start a harvest on AReS
2023-01-18
- I’m looking at all the ORCID identifiers in the database, which seem to be way more than I realized:
localhost/dspacetest= ☘ \COPY (SELECT DISTINCT(text_value) FROM metadatavalue WHERE dspace_object_id IN (SELECT uuid FROM item) AND metadata_field_id=247) to /tmp/2023-01-18-orcid-identifiers.txt;
COPY 4231
$ cat ~/src/git/DSpace/dspace/config/controlled-vocabularies/cg-creator-identifier.xml /tmp/2023-01-18-orcid-identifiers.txt | grep -oE '[A-Z0-9]{4}-[A-Z0-9]{4}-[A-Z0-9]{4}-[A-Z0-9]{4}' | sort -u > /tmp/2023-01-18-orcids.txt
$ wc -l /tmp/2023-01-18-orcids.txt
4518 /tmp/2023-01-18-orcids.txt
- Then I resolved them from ORCID and updated them in the database:
$ ./ilri/resolve-orcids.py -i /tmp/2023-01-18-orcids.txt -o /tmp/2023-01-18-orcids-names.txt -d
$ ./ilri/update-orcids.py -i /tmp/2023-01-18-orcids-names.txt -db dspace -u dspace -p 'fuuu' -m 247
- Then I updated the controlled vocabulary
- CGSpace became inactive in the afternoon, with a high number of locks, but surprisingly low CPU usage:
$ psql -c 'SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa ON pl.pid = psa.pid;' | grep -o -E '(dspaceWeb|dspaceApi|dspaceCli)' | sort | uniq -c
83 dspaceApi
7829 dspaceWeb
- In the DSpace logs I see some weird SQL messages, so I decided to restart PostgreSQL and Tomcat 7…
- I hope this doesn’t cause some issue with in-progress workflows…
- I see another user on Cox in the US (98.186.216.144) crawling and scraping XMLUI with Python
- I will add python to the list of bad bot user agents in nginx
- While looking into the locks I see some potential Java heap issues
- Indeed, I see two out of memory errors in Tomcat’s journal:
tomcat7[310996]: java.lang.OutOfMemoryError: Java heap space
tomcat7[310996]: Jan 18, 2023 1:37:03 PM org.apache.tomcat.jdbc.pool.ConnectionPool abandon
- Which explains why the locks went down to normal numbers as I was watching… (because Java crashed)
2023-01-19
- Update a bunch of ORCID identifiers, Initiative mappings, and regions on CGSpace
- So it seems an IFPRI user got caught up in the blocking I did yesterday
- Their ISP is Comcast…
- I need to re-work the ASN blocking on nginx, but for now I will just get the ASNs again minus Comcast:
$ wget https://asn.ipinfo.app/api/text/list/AS714 \
https://asn.ipinfo.app/api/text/list/AS16276 \
https://asn.ipinfo.app/api/text/list/AS15169 \
https://asn.ipinfo.app/api/text/list/AS23576 \
https://asn.ipinfo.app/api/text/list/AS24940 \
https://asn.ipinfo.app/api/text/list/AS13238 \
https://asn.ipinfo.app/api/text/list/AS32934 \
https://asn.ipinfo.app/api/text/list/AS14061 \
https://asn.ipinfo.app/api/text/list/AS12876 \
https://asn.ipinfo.app/api/text/list/AS55286 \
https://asn.ipinfo.app/api/text/list/AS203020 \
https://asn.ipinfo.app/api/text/list/AS204287 \
https://asn.ipinfo.app/api/text/list/AS50245 \
https://asn.ipinfo.app/api/text/list/AS6939 \
https://asn.ipinfo.app/api/text/list/AS16509 \
https://asn.ipinfo.app/api/text/list/AS14618
$ cat AS* | sort | uniq | wc -l
18179
$ cat /tmp/AS* | ~/go/bin/mapcidr -a > /tmp/networks.txt
$ wc -l /tmp/networks.txt
5872 /tmp/networks.txt
2023-01-20
- A lot of work on CGSpace metadata (ORCID identifiers, regions, and Initiatives)
- I noticed that MEL and CGSpace are using slightly different vocabularies for SDGs so I sent an email to Salem and Sara
2023-01-21
- Export the Initiatives community again to perform collection mappings and country/region fixes
2023-01-22
- There has been a high load on the server for a few days, currently 8.0… and I’ve been seeing some PostgreSQL locks stuck all day:
$ psql -c 'SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa ON pl.pid = psa.pid;' | grep -o -E '(dspaceWeb|dspaceApi|dspaceCli)' | sort | uniq -c
11 dspaceApi
28 dspaceCli
981 dspaceWeb
- Looking at the locks I see they are from this morning at 5:00 AM, which is the
dspace checker-emailscript- Last week I disabled the one that ones at 4:00 AM, but I guess I will experiment with disabling this too…
- Then I killed the PIDs of the locks
$ psql -c "SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa ON pl.pid = psa.pid WHERE application_name='dspaceCli';" | less -S
...
$ ps auxw | grep 18986
postgres 1429108 1.9 1.5 3359712 508148 ? Ss 05:00 13:40 postgres: 12/main: dspace dspace 127.0.0.1(18986) SELECT
- Also, I checked the age of the locks and killed anything over 1 day:
$ psql < locks-age.sql | grep days | less -S
- Then I ran all updates on the server and restarted it…
- Salem responded to my question about the SDG mismatch between MEL and CGSpace
- We agreed to use a version based on the text of this site
- Salem is having issues with some REST API submission / updates
- I updated DSpace Test with a recent CGSpace backup and created a super admin user for him to test
- Clean and normalize fifty-eight IFPRI records for batch import to CGSpace
- I did a duplicate check and found six, so that’s good!
- I exported the entire CGSpace to check for missing Initiative mappings
- Then I exported the Initiatives community to check for missing regions
- Then I ran the script to check for missing ORCID identifiers
- Then finally, I started a harvest on AReS
2023-01-23
- Salem found that you can actually harvest everything in DSpace 7 using the
discover/browsesendpoint - Exported CGSpace again to examine and clean up a bunch of stuff like ISBNs in the ISSN field, DOIs in the URL field, dataset URLs in the DOI field, normalized a bunch of publisher places, fixed some countries and regions, fixed some licenses, etc
- I noticed that we still have “North America” as a region, but according to UN M.49 that is the continent, which comprises “Northern America” the region, so I will update our controlled vocabularies and all existing entries
- I imported changes to 1,800 items
- When it finished five hours later I started a harvest on AReS
2023-01-24
- Proof and upload seven items for the Rethinking Food Markets Initiative for IFPRI
- Export CGSpace to do some minor cleanups, Initiative collection mappings, and region fixes
- I also added “CGIAR Trust Fund” to all items with an Initiative in
cg.contributor.initiative
- I also added “CGIAR Trust Fund” to all items with an Initiative in
2023-01-25
- Oh shit, the import last night ran for twelve hours and then died:
Error committing changes to database: could not execute statement
Aborting most recent changes.
- I re-submitted a smaller version without the CGIAR Trust Fund changes for now just so we get the regions and other fixes
- Do some work on SAPLING issues for CGSpace, sending a large list of issues we found to the MEL team for items they submitted
- Abenet noticed that the number of items in the Initiatives community appears to have dropped by about 2,000 in the XMLUI
- We looked on AReS and all the items are still there
- I looked in the DSpace log and see around 2,000 messages like this:
2023-01-25 07:14:59,529 ERROR com.atmire.versioning.ModificationLogger @ Error while writing item to versioning index: c9fac1f2-6b2b-4941-8077-40b7b5c936b6 message:missing required field: epersonID
org.apache.solr.client.solrj.impl.HttpSolrServer$RemoteSolrException: missing required field: epersonID
at org.apache.solr.client.solrj.impl.HttpSolrServer.executeMethod(HttpSolrServer.java:552)
at org.apache.solr.client.solrj.impl.HttpSolrServer.request(HttpSolrServer.java:210)
at org.apache.solr.client.solrj.impl.HttpSolrServer.request(HttpSolrServer.java:206)
at org.apache.solr.client.solrj.request.AbstractUpdateRequest.process(AbstractUpdateRequest.java:124)
at org.apache.solr.client.solrj.SolrServer.add(SolrServer.java:116)
at org.apache.solr.client.solrj.SolrServer.add(SolrServer.java:102)
at com.atmire.versioning.ModificationLogger.indexItem(ModificationLogger.java:263)
at com.atmire.versioning.ModificationConsumer.end(ModificationConsumer.java:134)
at org.dspace.event.BasicDispatcher.dispatch(BasicDispatcher.java:157)
at org.dspace.core.Context.dispatchEvents(Context.java:455)
at org.dspace.core.Context.commit(Context.java:424)
at org.dspace.core.Context.complete(Context.java:380)
at org.dspace.app.bulkedit.MetadataImport.main(MetadataImport.java:1399)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.dspace.app.launcher.ScriptLauncher.runOneCommand(ScriptLauncher.java:229)
at org.dspace.app.launcher.ScriptLauncher.main(ScriptLauncher.java:81)
- I filed a ticket with Atmire to ask them
- For now I just did a light Discovery reindex (not the full one) and all the items appeared again
- Submit an issue to MEL GitHub regarding the capitalization of CRPs: https://github.com/CodeObia/MEL/issues/11133
- I talked to Salem and he said that this is a legacy thing from when CGSpace was using ALL CAPS for most of its metadata. I provided him with our current controlled vocabulary for CRPs and he will update it in MEL.
- On that note, Peter and Abenet and I realized that we still have an old field
cg.subject.crpwith about 450 values in it, but it has not been used for a few years (they are using the old ALL CAPS CRPs) - I exported this list of values to lowercase them and move them to
cg.contributor.crp - Even if some items end up with multiple CRPs, they will get de-duplicated when I remove duplicate values soon
$ ./ilri/fix-metadata-values.py -i /tmp/2023-01-25-fix-crp-subjects.csv -db dspace -u dspace -p 'fuuu' -f cg.subject.crp -t correct
$ ./ilri/move-metadata-values.py -i /tmp/2023-01-25-move-crp-subjects.csv -db dspace -u dspace -p 'fuuu' -f cg.subject.crp -t cg.contributor.crp
- After fixing and moving them all, I deleted the
cg.subject.crpfield from the metadata registry - I realized a smarter way to update the text lang attributes of metadata would be to restrict the query to items that are in the archive and not withdrawn:
UPDATE metadatavalue SET text_lang='en_US' WHERE dspace_object_id IN (SELECT uuid FROM item WHERE in_archive AND NOT withdrawn) AND text_lang IS NULL OR text_lang IN ('en', '');
-
I tried that in a transaction and it hung, so I canceled it and rolled back
-
I see some PostgreSQL locks attributed to
dspaceApithat were started at2023-01-25 13:40:04.529087+01and haven’t changed since then (that’s eight hours ago)- I killed the pid…
- There were also saw some locks owned by
dspaceWebthat were nine and four hours old, so I killed those too… - Now Maria was able to archive one submission of hers that was hanging all afternoon, but I still can’t run the update on the text langs…
-
Export entire CGSpace to do Initiative mappings again
-
Started a harvest on AReS
2023-01-26
- Export entire CGSpace to do some metadata cleanup on various fields
- I also added “CGIAR Trust Fund” to all items in the Initiatives community
2023-01-27
- Export a list of affiliations in the Initiatives community for Peter, trying a new method to avoid exporting everything from PostgreSQL:
$ dspace metadata-export -i 10568/115087 -f /tmp/2023-01-27-initiatives.csv
$ csvcut -c 'cg.contributor.affiliation[en_US]' 2023-01-27-initiatives.csv \
| sed -e 1d -e 's/^"//' -e 's/"$//' -e 's/||/\n/g' -e '/^$/d' \
| sort | uniq -c | sort -h \
| awk 'BEGIN { FS = "^[[:space:]]+[[:digit:]]+[[:space:]]+" } {print $2}'\
| sed -e '1i cg.contributor.affiliation' -e 's/^\(.*\)$/"\1"/' \
> /tmp/2023-01-27-initiatives-affiliations.csv
- The first sed command strips the quotes, deletes empty lines, and splits multiple values on “||”
- The awk command sets the field separator to something so we can get the second “field” of the sort command, ie:
...
309 International Center for Agricultural Research in the Dry Areas
412 International Livestock Research Institute
- The second sed command adds the CSV header and quotes back
- I did the same for authors and donors and send them to Peter to make corrections
2023-01-28
- Daniel from the Alliance said they are getting an HTTP 401 when trying to submit items to CGSpace via the REST API
2023-01-29
- Export the entire CGSpace to do Initiatives collection mappings
- I was thinking about a way to use Crossref’s API to enrich our data, for example checking registered DOIs for license information, publishers, etc
- Turns out I had already written
crossref-doi-lookup.pylast year, and it works - I exported a list of all DOIs without licenses from CGSpace, minus the CIFOR ones because I know they aren’t registered on Crossref, which is about 11,800 DOIs
- Turns out I had already written
$ csvcut -c 'cg.identifier.doi[en_US]' ~/Downloads/2023-01-29-CGSpace-DOIs-without-licenses.csv \
| csvgrep -c 'cg.identifier.doi[en_US]' -r '.*cifor.*' -i \
| sed 1d > /tmp/2023-01-29-dois.txt
$ wc -l /tmp/2023-01-29-dois.txt
11819 /tmp/2023-01-29-dois.txt
$ ./ilri/crossref-doi-lookup.py -e a.orth@cgiar.org -i /tmp/2023-01-29-dois.txt -o /tmp/crossref-results.csv
$ csvcut -c 'id,cg.identifier.doi[en_US]' ~/Downloads/2023-01-29-CGSpace-DOIs-without-licenses.csv \
| sed -e 's_https://doi.org/__g' -e 's_https://dx.doi.org/__g' -e 's/cg.identifier.doi\[en_US\]/doi/' \
> /tmp/cgspace-temp.csv
$ csvjoin -c doi /tmp/cgspace-temp.csv /tmp/crossref-results.csv \
| csvgrep -c license -r 'creative' \
| sed '1s/license/dcterms.license[en_US]/' \
| csvcut -c id,license > /tmp/2023-01-29-new-licenses.csv
- The above was done with just 5,000 DOIs because it was taking a long time, but after the last step I imported into OpenRefine to clean up the license URLs
- Then I imported 635 new licenses to CGSpace woooo
- After checking the remaining 6,500 DOIs there were another 852 new licenses, woooo
- Peter finished the corrections on affiliations, authors, and donors
- I quickly checked them and applied each on CGSpace
- Start a harvest on AReS
2023-01-30
- Run the thumbnail fixer tasks on the Initiatives collections:
$ chrt -b 0 dspace dsrun io.github.ilri.cgspace.scripts.FixLowQualityThumbnails 10568/115087 | tee -a /tmp/FixLowQualityThumbnails.log
$ grep -c remove /tmp/FixLowQualityThumbnails.log
16
$ chrt -b 0 dspace dsrun io.github.ilri.cgspace.scripts.FixJpgJpgThumbnails 10568/115087 | tee -a /tmp/FixJpgJpgThumbnails.log
$ grep -c replacing /tmp/FixJpgJpgThumbnails.log
13
2023-01-31
- Someone from the Google Scholar team contacted us to ask why Googlebot is blocked from crawling CGSpace
- I said that I blocked them because they crawl haphazardly and we had high load during PRMS reporting
- Now I will unblock their ASN15169 in nginx…
- I urged them to be smarter about crawling since we’re a small team and they are a huge engineering company
- I removed their ASN and regenerted my list from 2023-01-17:
$ wget https://asn.ipinfo.app/api/text/list/AS714 \
https://asn.ipinfo.app/api/text/list/AS16276 \
https://asn.ipinfo.app/api/text/list/AS23576 \
https://asn.ipinfo.app/api/text/list/AS24940 \
https://asn.ipinfo.app/api/text/list/AS13238 \
https://asn.ipinfo.app/api/text/list/AS32934 \
https://asn.ipinfo.app/api/text/list/AS14061 \
https://asn.ipinfo.app/api/text/list/AS12876 \
https://asn.ipinfo.app/api/text/list/AS55286 \
https://asn.ipinfo.app/api/text/list/AS203020 \
https://asn.ipinfo.app/api/text/list/AS204287 \
https://asn.ipinfo.app/api/text/list/AS50245 \
https://asn.ipinfo.app/api/text/list/AS6939 \
https://asn.ipinfo.app/api/text/list/AS16509 \
https://asn.ipinfo.app/api/text/list/AS14618
$ cat AS* | sort | uniq | wc -l
17134
$ cat /tmp/AS* | ~/go/bin/mapcidr -a > /tmp/networks.txt
- Then I updated nginx…
- Re-run the scripts to delete duplicate metadata values and update item timestamps that I originally used in 2022-11
- This was about 650 duplicate metadata values…
- Exported CGSpace to do some metadata interrogation in OpenRefine
- I looked at items that are set as
Limited Accessbut have Creative Commons licenses - I filtered ~150 that had DOIs and checked them on the Crossref API using
crossref-doi-lookup.py - Of those, only about five or so were incorrectly marked as having Creative Commons licenses, so I set those to copyrighted
- For the rest, I set them to Open Access
- I looked at items that are set as
- Start a harvest on AReS