2022-12-01
- Fix some incorrect regions on CGSpace
- I exported the CCAFS and IITA communities, extracted just the country and region columns, then ran them through csv-metadata-quality to fix the regions
- Add a few more authors to my CSV with author names and ORCID identifiers and tag 283 items!
- Replace “East Asia” with “Eastern Asia” region on CGSpace (UN M.49 region)
Read more →
2022-11-01
- Last night I re-synced DSpace 7 Test from CGSpace
- I also updated all my local
7_x-dev branches on the latest upstreams
- I spent some time updating the authorizations in Alliance collections
- I want to make sure they use groups instead of individuals where possible!
- I reverted the Cocoon autosave change because it was more of a nuissance that Peter can’t upload CSVs from the web interface and is a very low severity security issue
Read more →
2022-10-01
- Start a harvest on AReS last night
- Yesterday I realized how to use GraphicsMagick with im4java and I want to re-visit some of my thumbnail tests
Read more →
2022-09-01
- A bit of work on the “Mapping CG Core–CGSpace–MEL–MARLO Types” spreadsheet
- I tested an item submission on DSpace Test with the Cocoon
org.apache.cocoon.uploads.autosave=false change
- The submission works as expected
- Start debugging some region-related issues with csv-metadata-quality
- I created a new test file
test-geography.csv with some different scenarios
- I also fixed a few bugs and improved the region-matching logic
Read more →
2022-08-01
Read more →
2022-07-02
- I learned how to use the Levenshtein functions in PostgreSQL
- The thing is that there is a limit of 255 characters for these functions in PostgreSQL so you need to truncate the strings before comparing
- Also, the trgm functions I’ve used before are case insensitive, but Levenshtein is not, so you need to make sure to lower case both strings first
Read more →
2022-06-06
- Look at the Solr statistics on CGSpace
- I see 167,000 hits from a bunch of Microsoft IPs with reverse DNS “msnbot-” using the Solr query
dns:*msnbot* AND dns:*.msn.com
- I purged these first so I could see the other “real” IPs in the Solr facets
- I see 47,500 hits from 80.248.237.167 on a data center ISP in Sweden, using a normal user agent
- I see 13,000 hits from 163.237.216.11 on a data center ISP in Australia, using a normal user agent
- I see 7,300 hits from 208.185.238.57 from Britanica, using a normal user agent
- There seem to be many more of these:
Read more →
2022-05-04
- I found a few more IPs making requests using the shady Chrome 44 user agent in the last few days so I will add them to the block list too:
- 18.207.136.176
- 185.189.36.248
- 50.118.223.78
- 52.70.76.123
- 3.236.10.11
- Looking at the Solr statistics for 2022-04
- 52.191.137.59 is Microsoft, but they are using a normal user agent and making tens of thousands of requests
- 64.39.98.62 is owned by Qualys, and all their requests are probing for /etc/passwd etc
- 185.192.69.15 is in the Netherlands and is using a normal user agent, but making excessive automated HTTP requests to paths forbidden in robots.txt
- 157.55.39.159 is owned by Microsoft and identifies as bingbot so I don’t know why its requests were logged in Solr
- 52.233.67.176 is owned by Microsoft and uses a normal user agent, but making excessive automated HTTP requests
- 157.55.39.144 is owned by Microsoft and uses a normal user agent, but making excessive automated HTTP requests
- 207.46.13.177 is owned by Microsoft and identifies as bingbot so I don’t know why its requests were logged in Solr
- If I query Solr for
time:2022-04* AND dns:*msnbot* AND dns:*.msn.com. I see a handful of IPs that made 41,000 requests
- I purged 93,974 hits from these IPs using my
check-spider-ip-hits.sh script
Read more →
2022-04-01
- I did G1GC tests on DSpace Test (linode26) to compliment the CMS tests I did yesterday
- The Discovery indexing took this long:
real 334m33.625s
user 227m51.331s
sys 3m43.037s
2022-04-04
- Start a full harvest on AReS
- Help Marianne with submit/approve access on a new collection on CGSpace
- Go back in Gaia’s batch reports to find records that she indicated for replacing on CGSpace (ie, those with better new copies, new versions, etc)
- Looking at the Solr statistics for 2022-03 on CGSpace
- I see 54.229.218.204 on Amazon AWS made 49,000 requests, some of which with this user agent:
Apache-HttpClient/4.5.9 (Java/1.8.0_322), and many others with a normal browser agent, so that’s fishy!
- The DSpace agent pattern
http.?agent seems to have caught the first ones, but I’ll purge the IP ones
- I see 40.77.167.80 is Bing or MSN Bot, but using a normal browser user agent, and if I search Solr for
dns:*msnbot* AND dns:*.msn.com. I see over 100,000, which is a problem I noticed a few months ago too…
- I extracted the MSN Bot IPs from Solr using an IP facet, then used the
check-spider-ip-hits.sh script to purge them
2022-04-10
- Start a full harvest on AReS
2022-04-13
- UptimeRobot mailed to say that CGSpace was down
- I looked and found the load at 44…
- There seem to be a lot of locks from the XMLUI:
$ psql -c 'SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa ON pl.pid = psa.pid;' | grep -o -E '(dspaceWeb|dspaceApi)' | sort | uniq -c | sort -n
3173 dspaceWeb
- Looking at the top IPs in nginx’s access log one IP in particular stands out:
941 66.249.66.222
1224 95.108.213.28
2074 157.90.209.76
3064 66.249.66.221
95743 185.192.69.15
- 185.192.69.15 is in the UK
- I added a block for that IP in nginx and the load went down…
2022-04-16
2022-04-18
- I woke up to several notices from UptimeRobot that CGSpace had gone down and up in the night (of course I’m on holiday out of the country for Easter)
- I see there are many locks in use from the XMLUI:
$ psql -c 'SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa ON pl.pid = psa.pid;' | grep -o -E '(dspaceWeb|dspaceApi)' | sort | uniq -c
8932 dspaceWeb
- Looking at the top IPs making requests it seems they are Yandex, bingbot, and Googlebot:
# cat /var/log/nginx/access.log /var/log/nginx/access.log.1 | awk '{print $1}' | sort | uniq -c | sort -h
752 69.162.124.231
759 66.249.64.213
864 66.249.66.222
905 2a01:4f8:221:f::2
1013 84.33.2.97
1201 157.55.39.159
1204 157.55.39.144
1209 157.55.39.102
1217 157.55.39.161
1252 207.46.13.177
1274 157.55.39.162
2553 66.249.66.221
2941 95.108.213.28
- One IP is using a stange user agent though:
84.33.2.97 - - [18/Apr/2022:00:20:38 +0200] "GET /bitstream/handle/10568/109581/Banana_Blomme%20_2020.pdf.jpg HTTP/1.1" 404 10890 "-" "SomeRandomText"
- Overall, it seems we had 17,000 unique IPs connecting in the last nine hours (currently 9:14AM and log file rolled over at 00:00):
# cat /var/log/nginx/access.log | awk '{print $1}' | sort | uniq | wc -l
17314
- That’s a lot of unique IPs, and I see some patterns of IPs in China making ten to twenty requests each
- The ISPs I’ve seen so far are ChinaNet and China Unicom
- I extracted all the IPs from today and resolved them:
# cat /var/log/nginx/access.log | awk '{print $1}' | sort | uniq > /tmp/2022-04-18-ips.txt
$ ./ilri/resolve-addresses-geoip2.py -i /tmp/2022-04-18-ips.txt -o /tmp/2022-04-18-ips.csv
$ csvcut -c 2 /tmp/2022-04-18-ips.csv | sed 1d | sort | uniq -c | sort -n | tail -n 10
102 GOOGLE
139 Maxihost LTDA
165 AMAZON-02
393 "China Mobile Communications Group Co., Ltd."
473 AMAZON-AES
616 China Mobile communications corporation
642 M247 Ltd
2336 HostRoyale Technologies Pvt Ltd
4556 Chinanet
5527 CHINA UNICOM China169 Backbone
$ csvcut -c 4 /tmp/2022-04-18-ips.csv | sed 1d | sort | uniq -c | sort -n | tail -n 10
139 262287
165 16509
180 204287
393 9808
473 14618
615 56041
642 9009
2156 203020
4556 4134
5527 4837
- I spot checked a few IPs from each of these and they are definitely just making bullshit requests to Discovery and HTML sitemap etc
- I will download the IP blocks for each ASN except Google and Amazon and ban them
$ wget https://asn.ipinfo.app/api/text/nginx/AS4837 https://asn.ipinfo.app/api/text/nginx/AS4134 https://asn.ipinfo.app/api/text/nginx/AS203020 https://asn.ipinfo.app/api/text/nginx/AS9009 https://asn.ipinfo.app/api/text/nginx/AS56041 https://asn.ipinfo.app/api/text/nginx/AS9808
$ cat AS* | sed -e '/^$/d' -e '/^#/d' -e '/^{/d' -e 's/deny //' -e 's/;//' | sort | uniq | wc -l
20296
- I extracted the IPv4 and IPv6 networks:
$ cat AS* | sed -e '/^$/d' -e '/^#/d' -e '/^{/d' -e 's/deny //' -e 's/;//' | grep ":" | sort > /tmp/ipv6-networks.txt
$ cat AS* | sed -e '/^$/d' -e '/^#/d' -e '/^{/d' -e 's/deny //' -e 's/;//' | grep -v ":" | sort > /tmp/ipv4-networks.txt
- I suspect we need to aggregate these networks since they are so many and nftables doesn’t like it when they overlap:
$ wc -l /tmp/ipv4-networks.txt
15464 /tmp/ipv4-networks.txt
$ aggregate6 /tmp/ipv4-networks.txt | wc -l
2781
$ wc -l /tmp/ipv6-networks.txt
4833 /tmp/ipv6-networks.txt
$ aggregate6 /tmp/ipv6-networks.txt | wc -l
338
- I deployed these lists on CGSpace, ran all updates, and rebooted the server
- This list is SURELY too broad because we will block legitimate users in China… but right now how can I discern?
- Also, I need to purge the hits from these 14,000 IPs in Solr when I get time
- Looking back at the Munin graphs a few hours later I see this was indeed some kind of spike that was out of the ordinary:
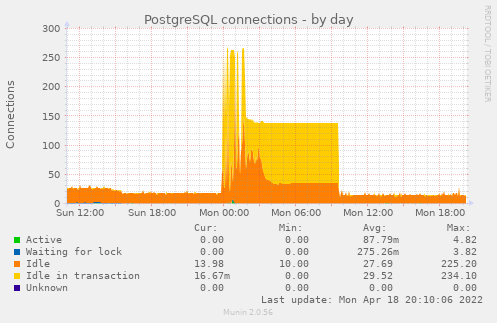
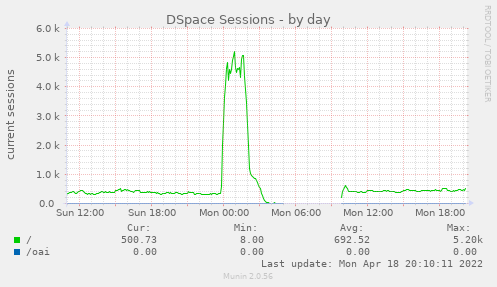
Read more →
2022-03-01
- Send Gaia the last batch of potential duplicates for items 701 to 980:
$ csvcut -c id,dc.title,dcterms.issued,dcterms.type ~/Downloads/2022-03-01-CGSpace-TAC-ICW-batch4-701-980.csv > /tmp/tac4.csv
$ ./ilri/check-duplicates.py -i /tmp/tac4.csv -db dspace -u dspace -p 'fuuu' -o /tmp/2022-03-01-tac-batch4-701-980.csv
$ csvcut -c id,filename ~/Downloads/2022-03-01-CGSpace-TAC-ICW-batch4-701-980.csv > /tmp/tac4-filenames.csv
$ csvjoin -c id /tmp/2022-03-01-tac-batch4-701-980.csv /tmp/tac4-filenames.csv > /tmp/2022-03-01-tac-batch4-701-980-filenames.csv